How many times have we gone through the routine of seeing data issue after data issue when something goes live in production, no matter how much of due-diligence was put in place? Despite having industry leading frameworks, operating models, air-tight processes, best-in-class templates, data issues creep in at multiple touch-points. Based on my assessment of UAT/post Go-Live scenario at various clients, more than 60% of the issues faced is related to data. Some of the organizations assessed had some sort of a piecemeal approach (or a quick fix in their parlance) to reduce data issues but it was more reactive and not sufficient, foolproof, scalable and/or repeatable.
The project types assessed include data migration, data integration, data transformation and creating/enhancing a bunch of analytical reports. In all the scenarios, data issue topped the charts as the number one pain area to be addressed. This is because the “data” aspect was either overlooked or not given the required level of importance. None of the processes were designed keeping data as the core/foundation. Everyone understands that data is an asset, yet no one has designed the frameworks models and processes keeping data as the key focus. It is just one module or component in the entire spectrum of things. Addressing all aspects around data in a systematic manner in addition to the existing parameters is key to reducing data issues.
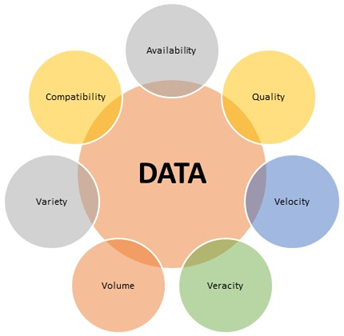
Figure: 1 – Key areas around data
Figure 1 shows some of the key areas that need to be addressed around data as a bare minimum to reduce data related issues.
A conceptual “Data Readiness” framework that can be customized and scaled up as required to suit various project types is shown here. Conducting an end-to-end data readiness check using such a well-defined framework, covering all major touch-points for data will help address data related issues early. While this framework is predominantly helpful during the approval/kick-off phase of projects, it extends all the way till the project goes live and declared stable.

Figure: 2 – Base framework for Data readiness
This highly scalable and customizable framework comes with supporting artifact(s) for each area as applicable. Refer Figure 3 for details. These artifacts are spread across people, process and technology areas. This will automatically address issues like schedule overruns, cost overruns, rework, low user confidence on IT, etc. as it touches upon all the aspects related to data.

Figure: 3 – Supporting artifacts & checklist items
The biggest advantage of this framework is that it can be easily blended with any existing governance model and PMO model an organization might be following.
Introduction
As the organization grows organically or in-organically, there will be an infusion of multiple technologies, loss of governance and a drift away from the centralized model. In some organizations where the BI environment is not robust, there will be an increased usage of MS Excel and MS Access to meet various business needs like cross-functional reporting, dashboards, etc.
When the organization is small, one can cater to the business requirements by manually crunching numbers. But as it grows, factors like localization, compliance, availability and skill set of resources make it unmanageable and tedious. Similarly, when the usage of Excel spreadsheets grow the complexity also grows along with it (macros, interlinked excels, etc.)
There are various models and frameworks for rationalization available in the industry today. Each model designed to address a specific problem and offer an excellent short-term solution. Interestingly all these industry models lack two important factors. A governance component and pillars/enablers to sustain the effort and add value to the client.
Rationalization – The piece meal problem:
When the environment slowly starts to become unmanageable, organizations look towards rationalization as a solution. Some of the factors that lead to the need for rationalization are:
- Compliance issues
- License fees consuming a large portion of the revenue
- Consolidation of operations is a bottleneck
- Data inconsistency start to creep in
- Integration post merger or acquisition
- Analysts spending more time validating the data rather than analyzing the information
Generally organizations identify what needs rationalization based on what is impacting their revenue or productivity the most. E.g. Tool license fee. Consultants are then called to fix that particular problem and move on. There are two issues here:
- First, the consultant concentrates only on the problem at hand and does not validate the environment for the root cause to fix it permanently
- Second, the framework used by the consultant fixes the problem perfectly from a short-term perspective and does not guarantee a long-term solution
The Solution:
Rationalization models in the industry today needs an update for inclusion of a governance component to help assess, rectify and sustain the rationalization effort in the long run. In addition to this, enabling components needs to be identified and included to add value to the overall exercise.
 Figure 1
Figure 1
A typical rationalization model with governance component and post rationalization enablers would look as shown in Figure 2. This model is not comprehensive and shows only the most common rationalization scenarios.
Pre-Rationalization Assessment
A pre-assessment when conducted would evaluate if the requested rationalization is all that is required to fix the existing problems or something more is needed for a permanent fix. Typically a root cause analysis helps identify the actual reason behind the current scenario. Along with this, the existing governance maturity and value creation opportunities are also identified to help enhance the user experience, adoption, sustainability and stability of the environment.
A simple excel questionnaire should help initiate the pre-assessment phase (Contact the author if you are interested in this excel) without dwelling deep in trying to understand the intricacies in the environment. Based on the assessment findings, the course of the rationalization exercise can be altered. For example, a formal Data Governance program kicked off in parallel.
Rationalize
This is the phase where the actual rationalization takes place using customized models and frameworks. Complete inventory gathering, metadata analysis, business discussions to understand the needs, etc. is performed. At this point, the client’s need from a short-term perspective is met. Sustainability of the environment would still be questionable.
Governance Component
The depth of coverage for the governance component is to be mutually decided between the client and consultant based on environmental factors. Parameters like size of the IT team, existing processes and policies, maturity, etc. play a major role in deciding the depth required.
The governance component introduced within the rationalization framework would typically deep-dive into the system to understand the policies & standards, roles & responsibilities, etc from various perspectives to fix or find a work-around to the problem and ensure the scenario does not repeat itself.

Enablers
Post rationalization enablers have no dependency on either the rationalization effort or the governance component. This component is kicked off post the rationalization phase either as a separate project or as an extension to the rationalization phase. The enabling components though they are optional, will play a vital role in adding value to the client by sustaining the setup from a long-term perspective and user adoption perspective. On occasions where more than one enabler has been identified, it is sufficient if the key enabler is addressed on priority.
For example, if the client requests for report rationalization, there is a high probability that the data model was not flexible and hence the users were creating multiple reports or there was a training issue. This would have got identified during the pre-assessment phase and can be addressed as part of this phase by setting up something like a Global Report Shop. The governance component would have helped address a part of this issue by ensuring policies are in place to see that the users do not create reports at will and at the same time they are directed to the right team or process to meet their requirements.
Taking another example, if the client goes for a KPI and metrics standardization exercise, there is a good chance that there is a need for data model changes, dashboards to be recreated and analytic reports to be designed from scratch. This can be handled by setting up a core analytics team well in advance. If this was not identified and addressed as part of the KPI standardization project, users day-to-day activities would get hampered and result in poor adoption.
Benefits
Primary advantages of this rationalization model are:
- Maximum revenue realization in a short duration
- Helps sustain the quality of the environment
- Enhances users productivity and adoption
Conclusion
Rationalization must be seen from a broader and long-term perspective. Rationalization without addressing the governance component will not be strong and one without any supporting pillars like the enablers mentioned will not serve the long-term purpose.
Posted: June 18th, 2011
Categories:
Business Intelligence
Tags:
consolidation,
enablers,
framework,
governance,
KPI,
model,
portfolio,
rationalization,
report,
standardization
Comments:
7 Comments.
Focus on the concept. Not the name
Let me start with BICC and BI CoE. From what I have read till now in articles and books like “Business Intelligence for Dummies”, there is hardly any difference between the two. However, if there is a choice they prefer CoE over Competency Center. The reason quoted in the book “Business Intelligence for Dummies” By Swain Scheps is, the word “competence” has the connotation of bare minimum proficiency, giving the feeling of being damned by faint praise. Even though BICC will go well beyond mere proficiency, it sounds mere average.
Based on what I have been seeing till now, I would say there is more than a fine line of difference between BICC and BI COE. According to me, BI COE can be considered as a subset of BICC. While one can have a number of COEs each concentrating on a particular area like say, Data, Tools & Technology, process, etc. BICC is something that houses all these BI COEs under one single umbrella and manages them.
To bring in more clarity, these CoEs will manage the resources, define standards & processes and best practices within the scope of that CoE. Any framework or approach or methodology set up for monitoring the overall progress of these CoEs including shared assets, processes and technology will be performed by the BICC.

Now to create some controversy/initiate discussion here, lets bring in data governance (DG). Organizations either implement BICC or DG but not both. On a closer look, you will see that, these organizations that claim to implement DG and not BICC, over a period have actually expanded into what otherwise would have been done as part of a BICC initiative. As shown in the picture below, they started off with “Data” governance as the primary goal (Represented as point 1). Once the base was set, they realized that changes to other areas like infrastructure, tools, etc was needed and started to enter into that space and control them (Represented as point 2).

As you can see, point 3 is represented in dotted lines because it is not mandatory for the DG team to setup separate CoEs in this model. It’s a single, strong, core team (dedicated in some cases) that could have gone ahead and performed the job of various CoEs during the setup without actually setting up the CoE. In other cases, they would have setup small teams like one for technology as a whole and so on to quicken the process of implementation.
So to summarize, for me its something like this BICC > BI COE > Data Governance.
I am open to all kinds of feedback as I know I can be wrong. So please share your views on this topic.
Reference:
“Business Intelligence for Dummies” By Swain Scheps
http://www.executionmih.com/business-intelligence/competency-centre-competencies.php
Posted: January 17th, 2011
Categories:
Business Intelligence
Tags:
bicc,
bicoe,
dg
Comments:
No Comments.
The 3-Level approach
The 3-level approach (Figure 1) works well when the organization is serious, has the required funding, resources to execute and a mature Enterprise Information Management (EIM) setup.

In organizations where the IT team is pressurized to show tangible output for every penny invested, a 4-level approach as shown in Figure 2 can be adopted. The question, “Is it possible to divide this further into multiple levels?” might arise. The thumb rule is more the number of levels, the (substantial) tangible benefit business can see at every stage will reduce. So a faster turn-around with visible progress should be the mantra for a successful implementation.

The four level data governance implementation has been considered for this article as that’s more common in the industry today.
What do we need for Level-2?
To setup a ‘very basic’ DG practice leveraging the existing setup, a database with a few tables, some scripts to act as a trigger and an intranet portal should suffice. Note that this is just a starting point and hence focus would be on data quality and not data governance to begin with. As funds flow in, one can move from data quality monitoring to data quality control and from there to data governance.
Going online
The organizations existing intranet portal would be leveraged and the objective now is to take processes online one by one starting with the change management process. As part of Level-1 activities, the DG team would have already defined the process for change management and this would be used now. Steps to convert this process into something that can be monitored are as follows:
- Capture key fields to be used in the form. Example, Ticket ID, priority of change request, source & target systems affected, change description, etc.
- Design the form front end with the fields identified and link this with a database (MS Access, Oracle, MS SQL) at the backend. Mature organizations can leverage their SOA setup
- Define the process flow. Example, who raises the request, what happens next, who approves it, exceptions handling, etc. This detail would again come from the detail captured in the previous phase
- Now bring in the governance component to ensure that no change gets moved to production without going through this process

More the detail captured in step a, tighter will be the governance in step d. For example, if there is a field to capture the results of QA, automatically it will imply that the change that is moving to production has to move through QA (Dev – QA – Production). Assuming process has been defined to ensure QA compliance for approval of change request. Step c which talks about defining process flow can be accomplished using database triggers and/or procedures. If the organization already has a rule engine in place, it can be leveraged here.
As part of enhancement, this setup can be improved by addition of small bits like SLA tracking, report generation capability, etc. Report generation capability can help governance in a major way by helping the DG team to track various critical parameters like open requests, SLA breaches, requests moved to production through exception process, etc. This in turn will help the DG team to fine tune processes and improve their maturity.
Moving ahead and taking another process online, say BI Tools & Technology control. The steps shown in figure 3 are applicable here also. The difference would be in steps c and d, where the process is defined and governed.
Some of the other processes that can be brought under the governance control without too much of cost and effort are:
- Database related activities (E.g. New DB creation, index creation)
- Data quality dashboard (E.g. rejected records list pulled from ETL, data certification status)
- Data security (E.g. user access to systems)
- Training tracker
In addition to this, various database triggers can be set to increase response levels. Primary advantage of getting to this stage is that the users would now be conversant with various processes in the organization and adapted to them. Some amount of governance would also have been established to move to the next level.
What next?
The organization can now consider moving to the next level by creating self-healing mechanisms wherever applicable. More advanced tools like say Kalido can be considered if required to improve the DG maturity level.
I’m really bored today hence posting this blog without much thought. Will definitely refine it later. Please do feed me with your comments to improve on this topic.
Posted: December 23rd, 2010
Categories:
Business Intelligence
Tags:
data governance,
dg
Comments:
No Comments.
Abstract
Giving data governance recommendations is easy but implementing them is altogether a different ball game. Organizations do realize the importance and value of data governance initiatives but when it comes to funding and prioritization of such initiatives, it always takes a lower priority. Over a period, governance becomes the root cause of a handful of the organizational issues and it is then when the organizations start to prioritize DG and bring in experts to set things right.
“Are these experts providing what the organization needs?”
“Is the problem of data governance solved when the expert leaves?”
“If not, what is it that is lurking and needs to be addressed?”
This article tries to throw light on the expectations of these organizations, what they get from the experts and how much of the recommendation can be converted or is converted to reality.
The Genesis
Problems related to data governance (DG) usually begin in an organization when investments in technology infrastructure and human resources are considered as assets but not the data itself. Businesses must understand that the backbone of their organization is ‘data’ and their competitiveness is determined by how data is managed internally across functions.
The problem of DG becomes critical as an organization grows in the absence of any formal oversight (i.e., a governance committee). Silos of technology seep in and lead to disruption of the enterprise architecture, followed by processes. In due course, data gets processed by the consumers of data. The impact of this is huge as users can now manipulate and publish data. The ripple effect of this can be felt on processes like change management that will now happen locally at users’ machines rather than going through a formally governed process.
The ‘In-house’ DG Team
The DG team is either dormant or virtual in most cases and often exists at either Level-1 (Lowest) or Level-2 in terms of maturity (on any model). The primary reason for this lack of maturity is the team’s unfamiliarity to DG processes beyond establishing naming standards, documentation of processes, identification of roles & responsibilities and a few other basic steps.
Even if the team is capable of setting up a DG practice, the business teams are not flexible enough to empower it sufficiently to establish a successful governance practice. In some cases, people identified to participate in the DG committee are already engaged in other business priorities such as, a program manager who is already tasked with multiple high-priority corporate development initiatives. This masks the true purpose of a DG team and makes it virtual.
The Problem
Firstly, the in-house teams do not have a well defined approach towards setting up DG processes; those with an approach are unable to define success metrics and those who manage to define the metrics, do not know how to put it into action.
According to the Quality Axiom,
“What cannot be defined cannot be measured;
What cannot be measured cannot be improved, and
What cannot be improved will eventually deteriorate.”
This is very much true in DG also. In DG, it is not enough to define metrics. Organizations need to be able to control and monitor them, too. The problem lies in setting up the infrastructure and control mechanisms capable of continuous monitoring. To solve this, a specialist is usually called for.
The Catch
The recommendations provided by the specialist often look very promising and implementable. The catch lies in the gap between what the organization expects and gets and how much of the recommendations can actually be implemented.
The first part, “Expectations of the organization” relates to the assessment of the existing state of DG and getting recommendations to solve the DG problem. The second part, “What the organization gets,” is where the mismatch happens. Most of the maturity models used by specialists, measure DG along the following five dimensions:
- Enterprise architecture
- Data lifecycle
- Data quality and controls
- Data security
- Oversight (funding, ownership, etc.)
The recommendations provided by these specialists traditionally pivot around these categories, but on a closer look, each of these categories have two components:
- Soft component (Level 1) – the easily implementable ones and
- Hard component (Level 2 & 3) – something which requires funding, effort and time to build
No matter how well the recommendations are categorized and sub categorized, these two components always exist. The soft components involving policy/process changes, re-organization, etc. are relatively easy to set up. However, the hard components that involve infrastructure, database, dashboards, etc. either get ignored or are partially implemented. It is this hard component that defines, “How many of the expert recommendations can be implemented?”
The 3-level approach (Figure 1) works well when the organization is serious, has the required funding, resources and wants to setup DG in a short time frame.
The Reality Check
Implementing DG is not as simple as buying a product off the shelf and installing it. Even specialists sometimes turn down requests for implementing these hard components because of inadequate Enterprise Information Management (EIM) maturity. EIM architecture involves data sourcing, integration, storage and dissemination. Setting up DG processes will be difficult even if one of these components is weak in terms of governance.
There are several pitfalls one must look out for. First, DG initiatives can result in power shifts and can be very difficult for senior management to accept since they have hitherto enjoyed ungoverned process authority. This aversion to change/give up power paves the way for something termed as a failure at Level-1 stage. This is an organization culture issue that needs to be addressed to move further.
Second, normally the specialists quote a price that involves setting up foundation elements such as changing the ETL infrastructure, setting up metadata, fixing master data, etc. to setup DG. The business, instead of considering the cost of getting these foundation elements up and running as individual investments, sees this expenditure as part of DG investment cost and fails to get the required funding. When a multi-year roadmap is proposed and funding is sought in the name of implementing DG every time, sponsors will hardly be enthusiastic about the investment. Also, through the initial phases of a DG engagement, tangible results are difficult to establish and showcase and hence the business might lose trust in the initiative. This can be termed as failure at Level-2 stage.
Conclusion
To enable a mature DG setup, organizations need to step back and take a look at their existing architecture, get the foundational elements in place, and finally push hard to implement the necessary hard and soft DG components. The cost of implementing these foundational elements should not be considered as a part of DG initiative, because doing so will only result in undercutting the priority and interest in this critical undertaking.
Data governance has to be an evolving process in an organization. A big bang overnight implementation of DG might not be always advisable unless the foundational components are in place.
Posted: November 30th, 2010
Categories:
Business Intelligence
Tags:
data governance,
dg,
reality
Comments:
No Comments.
